Efficient Diverse Ensemble for Discriminative Co-Tracking
CVPR'2018, Salt Lake City, Utah, USA, Jun 18-Jun 22, 2018
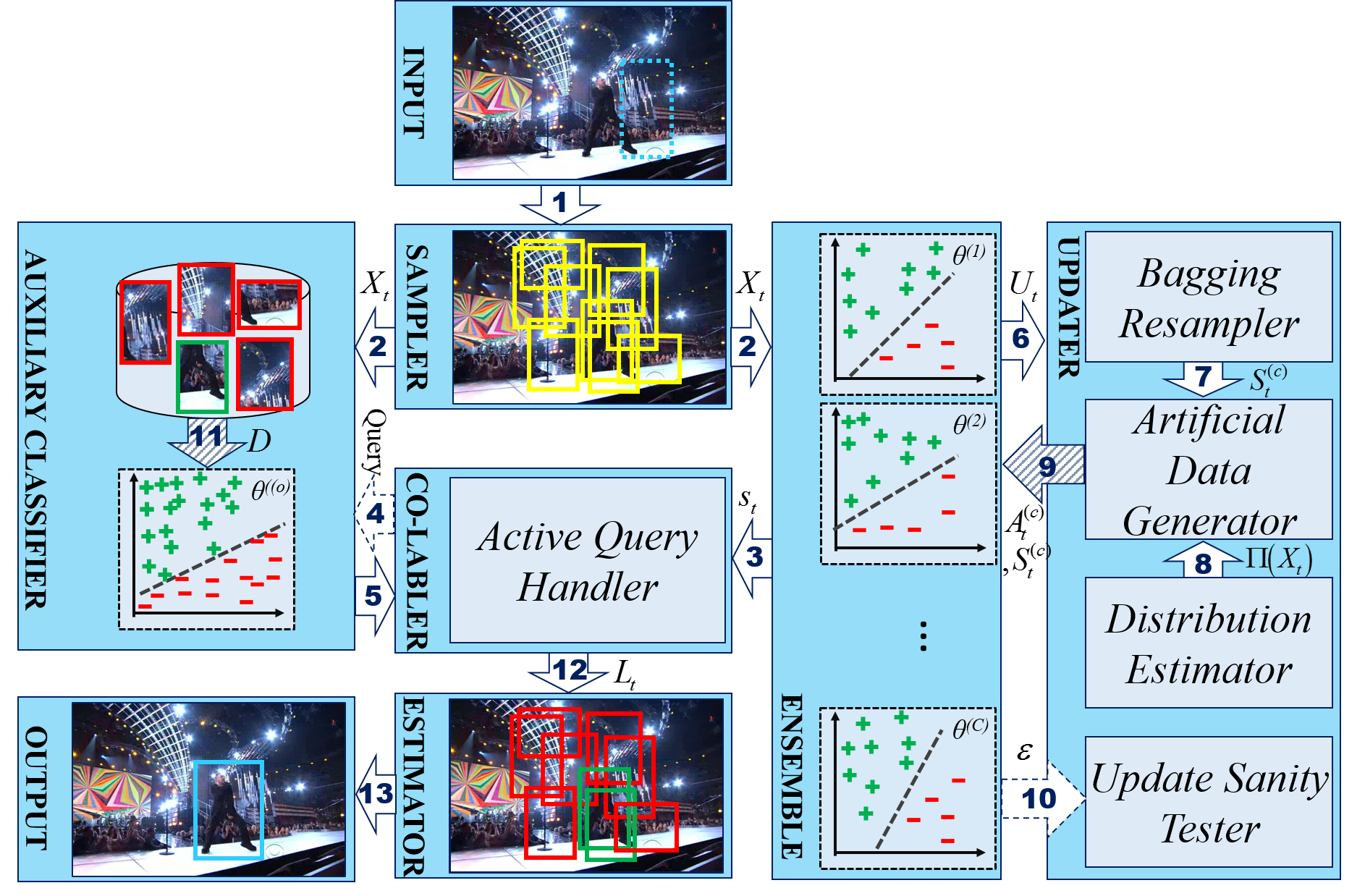
Ensemble discriminative tracking utilizes a committee of classifiers, to label data samples, which are in turn, used for retraining the tracker to localize the target using the collective knowledge of the committee. Committee members could vary in their features, memory update schemes, or training data, however, it is inevitable to have committee members that excessively agree because of large overlaps in their version space. To remove this redundancy and have an effective ensemble learning, it is critical for the committee to include consistent hypotheses that differ from one-another, covering the version space with minimum overlaps. In this study, we propose an online ensemble tracker that directly generates a diverse committee by generating an efficient set of artificial training. The artificial data is sampled from the empirical distribution of the samples taken from both target and background, whereas the process is governed by query-by-committee to shrink the overlap between classifiers. The experimental results demonstrate that the proposed scheme outperforms conventional ensemble trackers on public benchmarks.
Overview
The main challenge in ensemble methods is how to decorrelate ensemble members and diversify learned models. Combining the outputs of multiple classifiers is only useful if they disagree on some inputs, however, individual learners with the same training data are usually highly correlated.
We propose a diversified ensemble discriminative tracker (DEDT) for real-time object tracking. We construct an ensemble using various subsamples of the tracking data and maintain the ensemble throughout the tracking. This is possible by devising methods to update the ensemble to reflect target changes while keeping its diversity to achieve good accuracy and generalization. In addition, breaking the self-learning loop to avoid the potential drift of the ensemble is applied in a con-tracking framework with an auxiliary classifier. However, to avoid unnecessary computation and boost the accuracy of the tracker, an effective data exchange scheme is required. We demonstrate that learning ensembles with randomized subsets of training data along with artificial data with diverse labels in a co-tracking framework achieve superior accuracy. By generating artificial data with diverse labels, we intended to diversify the ensemble of classifiers, efficiently covering the version space, increasing the generalization of the ensemble, and as a result, improve the accuracy. In addition, by using the query-by-committee concept in labeling and updating stages of the tracker, the label noise problem is decreased because of updating classifiers only with the most informative samples.
 (a)
(a)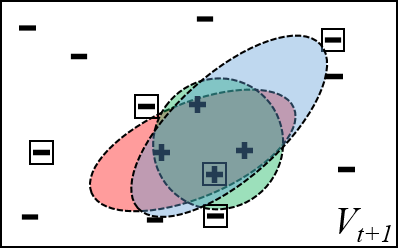 (b)
(b)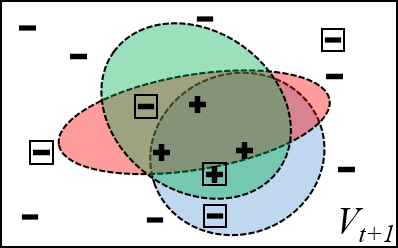 (c)
(c)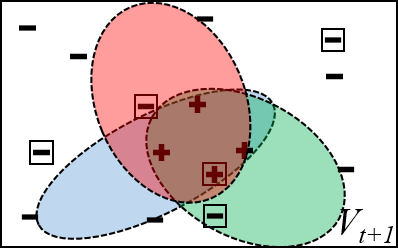 (d)
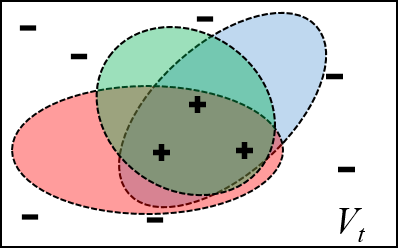
(d)Version space examples for ensemble classifiers. (a) All hypotheses are consistent with the previous labeled data, but each represents a different classifier in the version space $V_t$. In the next time step, the models are updated with the new data (boxed). (b) Updating with all of the data tend to make the hypothesis more overlapping. (c) Random subsets of training data are given to the hypotheses and they update without considering the rest of the data, the hypotheses cover random areas of the version space. (d) Random subsets of training data plus artificial generated data (proposed), trains the hypothese to be mutually uncorrelated as much as possible, while encouraging them to cover more (unexplored) area of the version space.
Poster
 Presented @ CVPR'18
Presented @ CVPR'18General Results
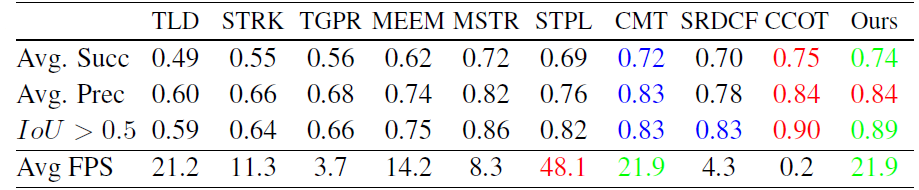 OTB 50
OTB 50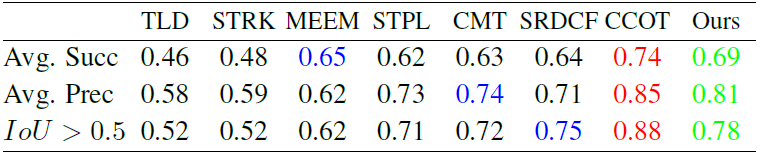 OTB 100
OTB 100 VOT 2015
VOT 2015Success Plots (OTB50)
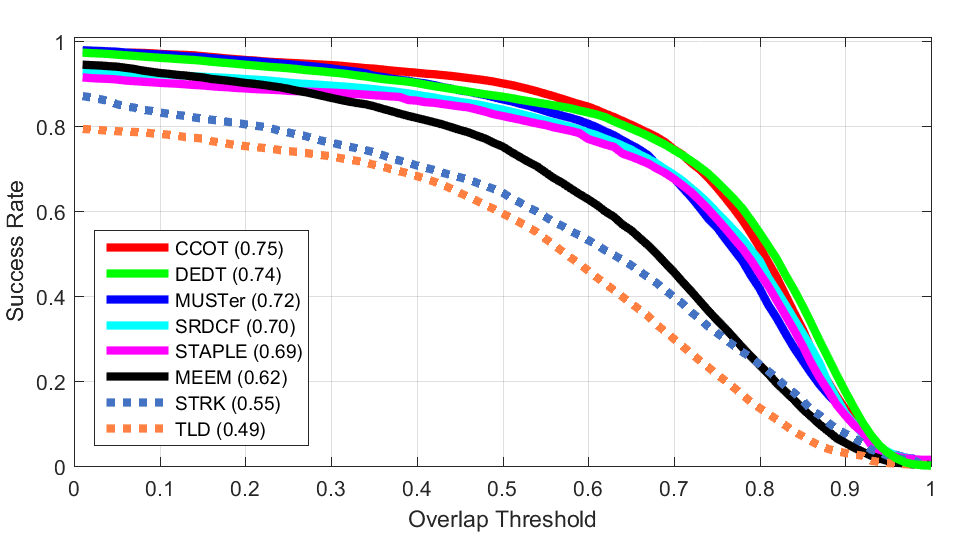 ALL
ALL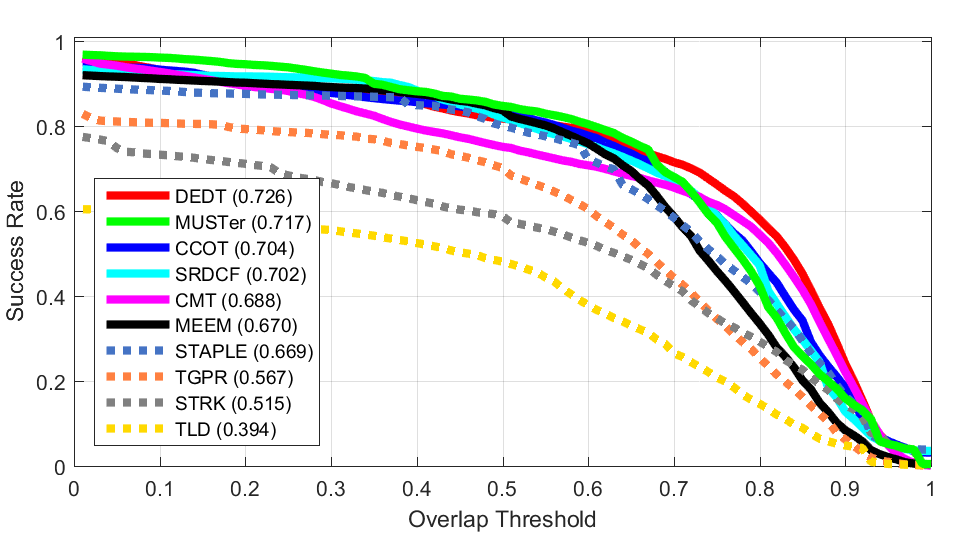 Clutter
Clutter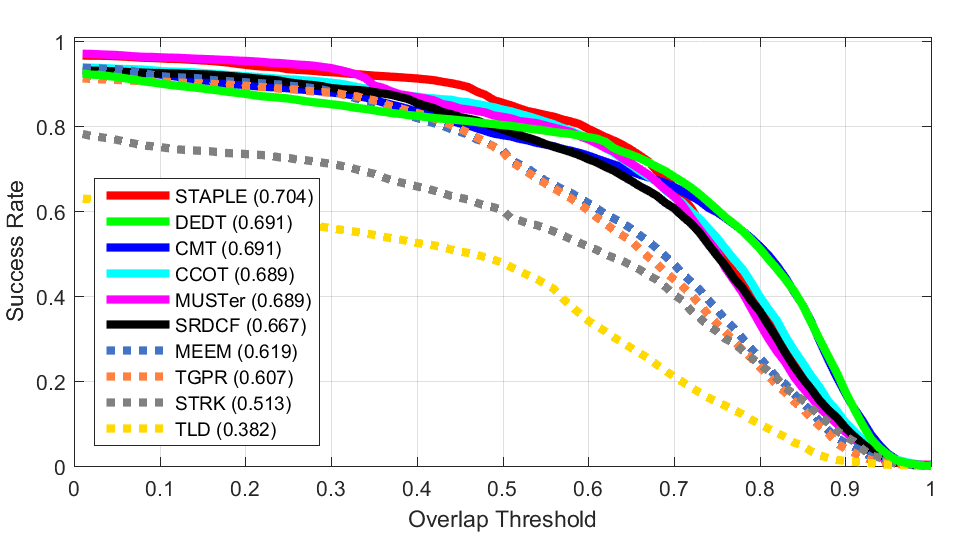 Deformation
Deformation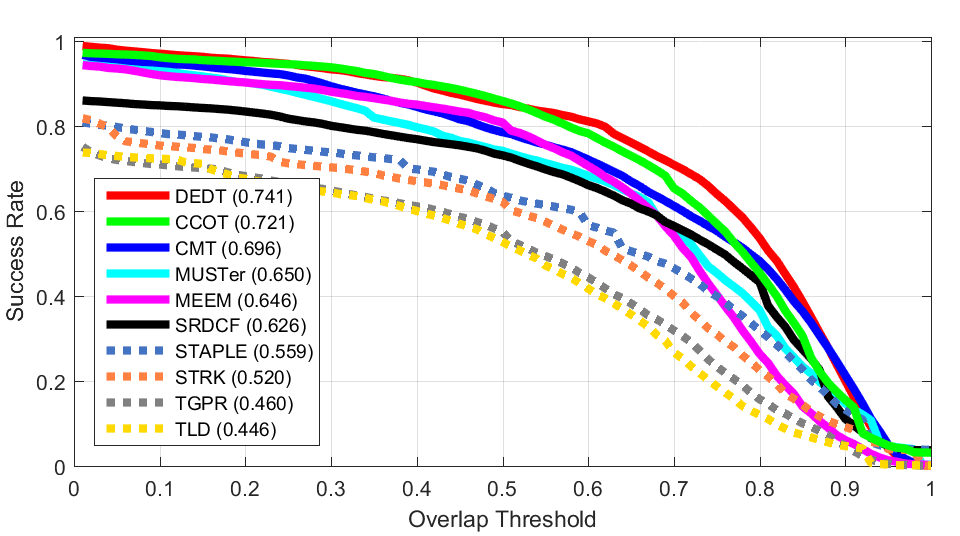 Fast
Fast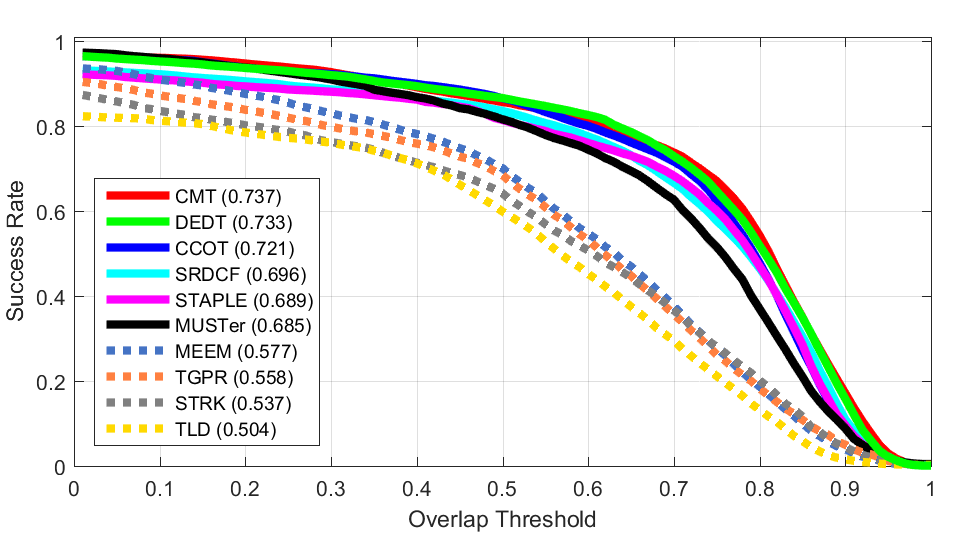 2D Rotation
2D Rotation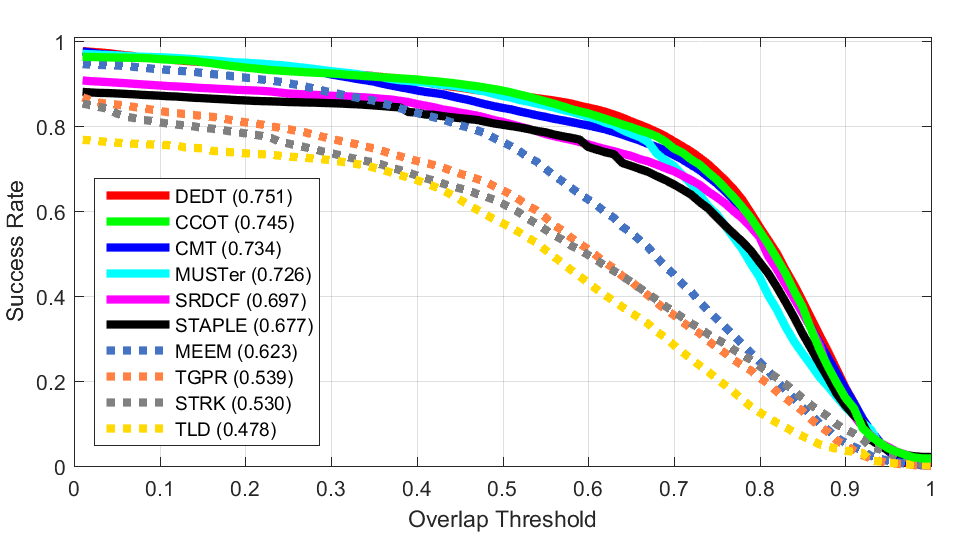 Lighting Change
Lighting Change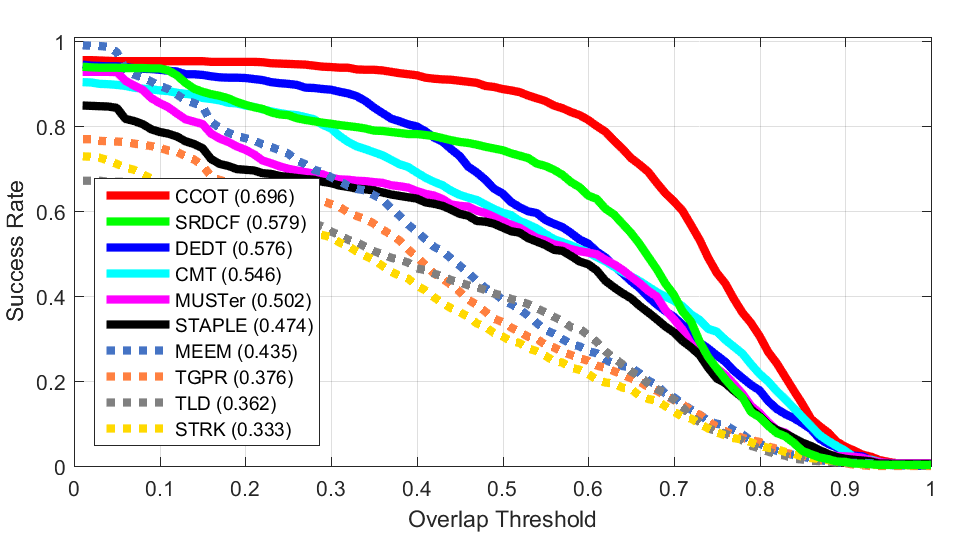 Low Resolution
Low Resolution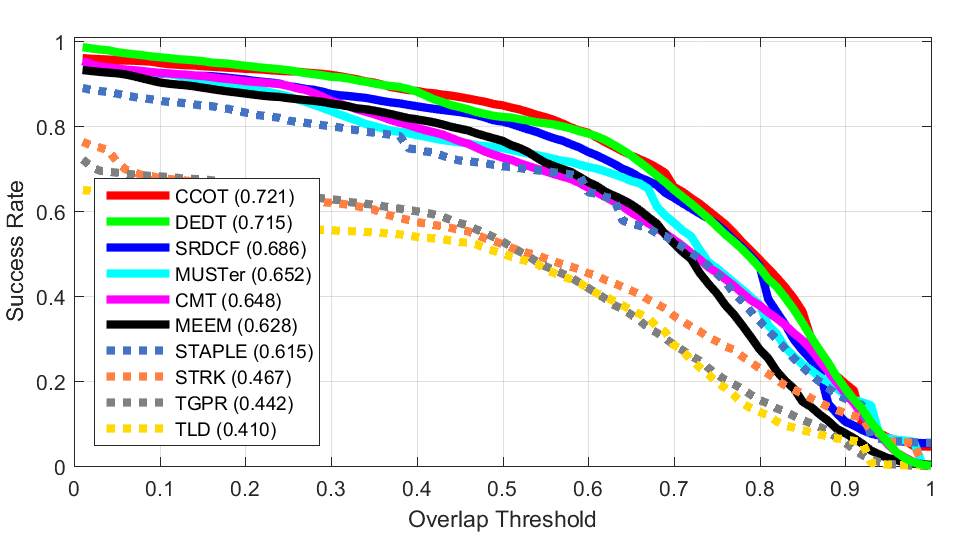 Blur
Blur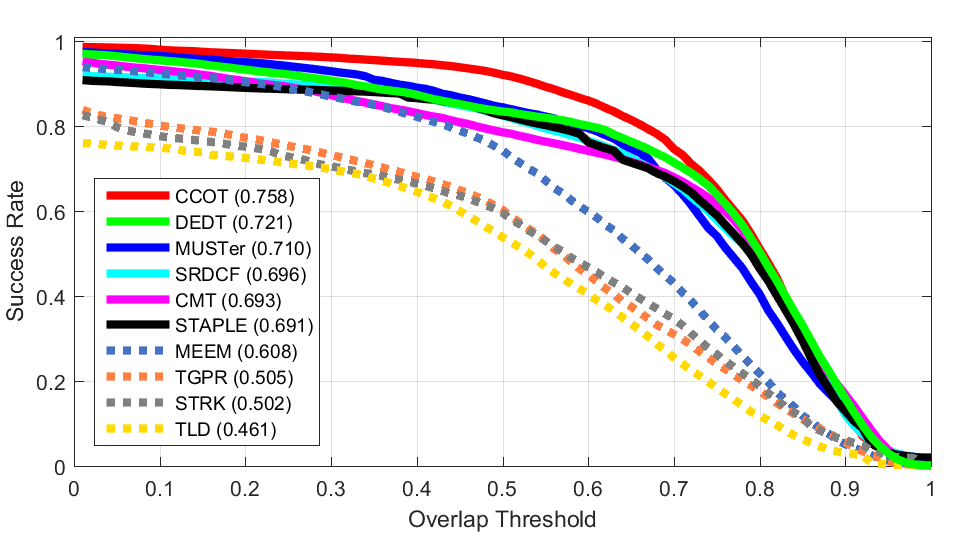 Occlusion
Occlusion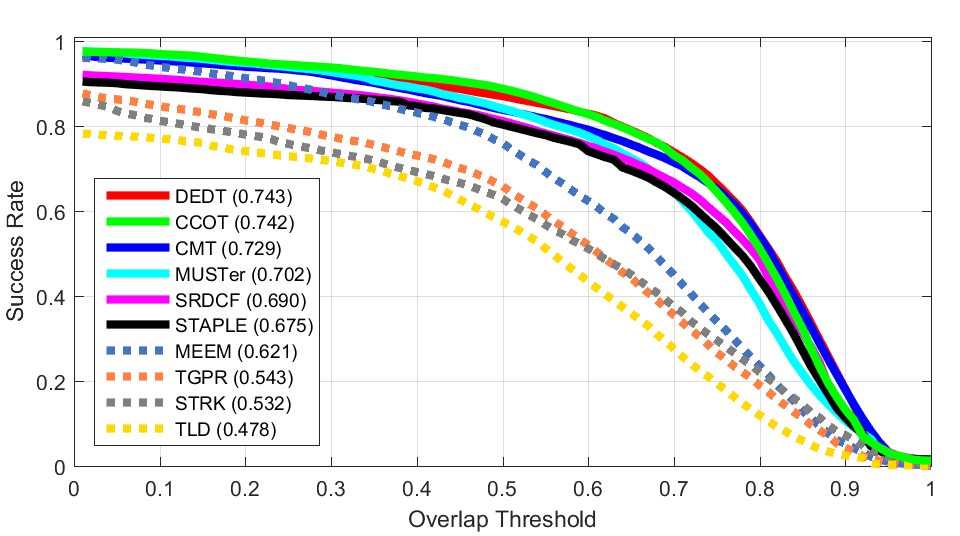 Z Rotation
Z Rotation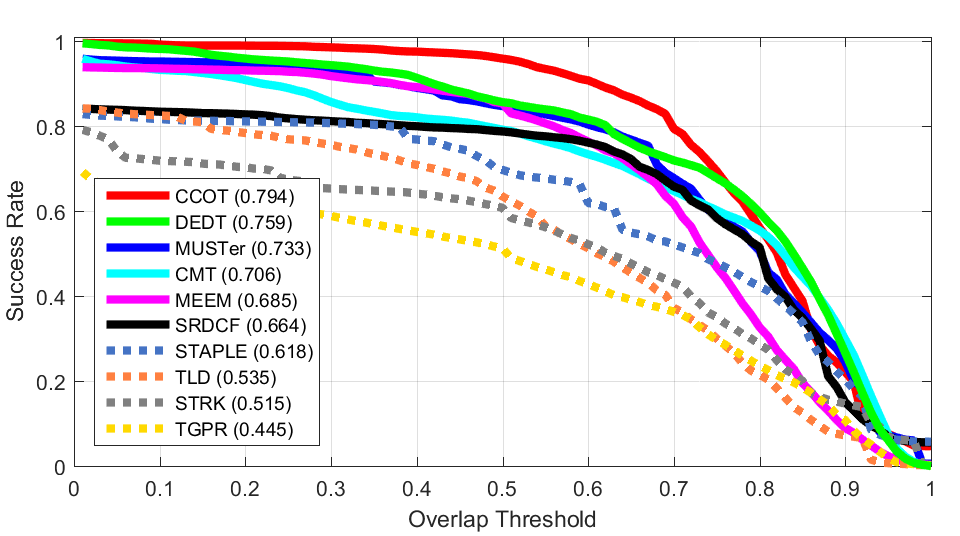 Shear
Shear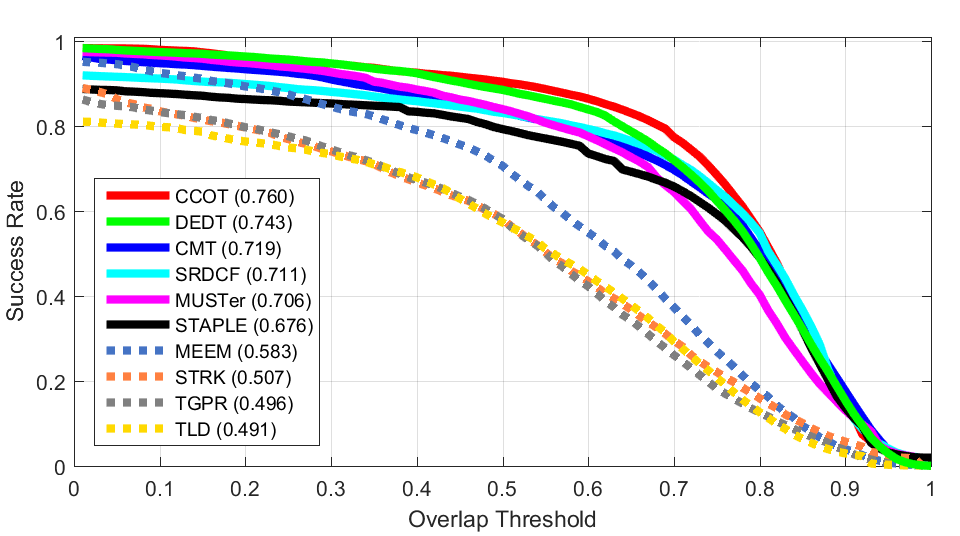 Scaling
Scaling
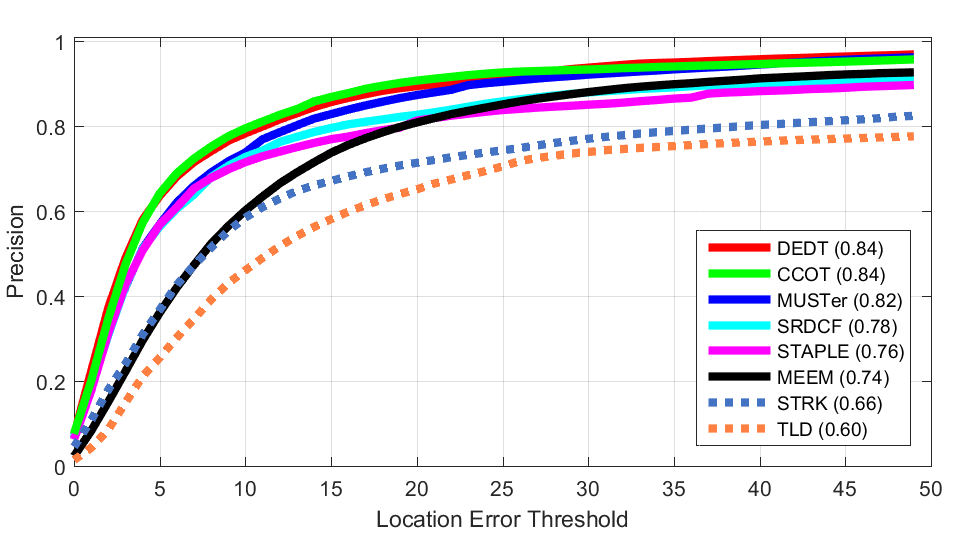 Precision Plot of ALL
Precision Plot of ALLSuccess Plots (OTB100)
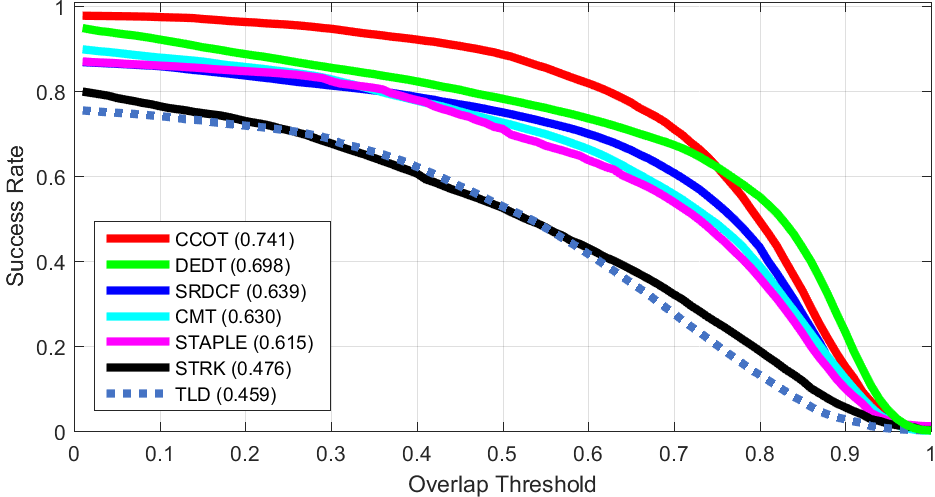 ALL
ALL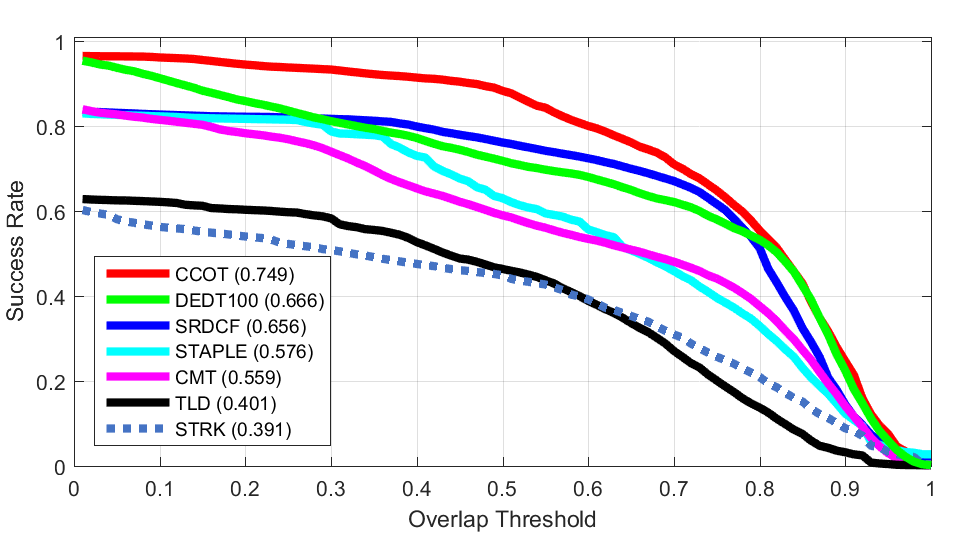 Clutter
Clutter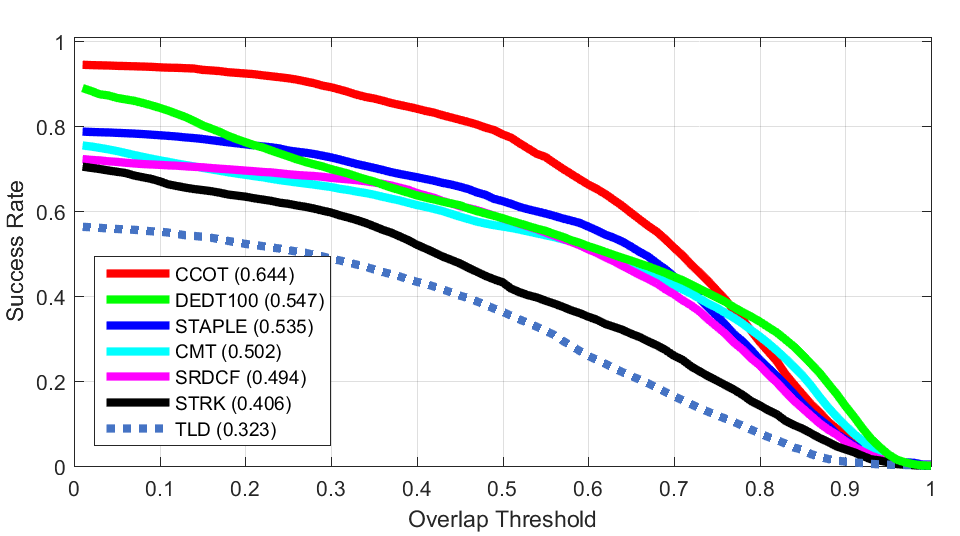 Deformation
Deformation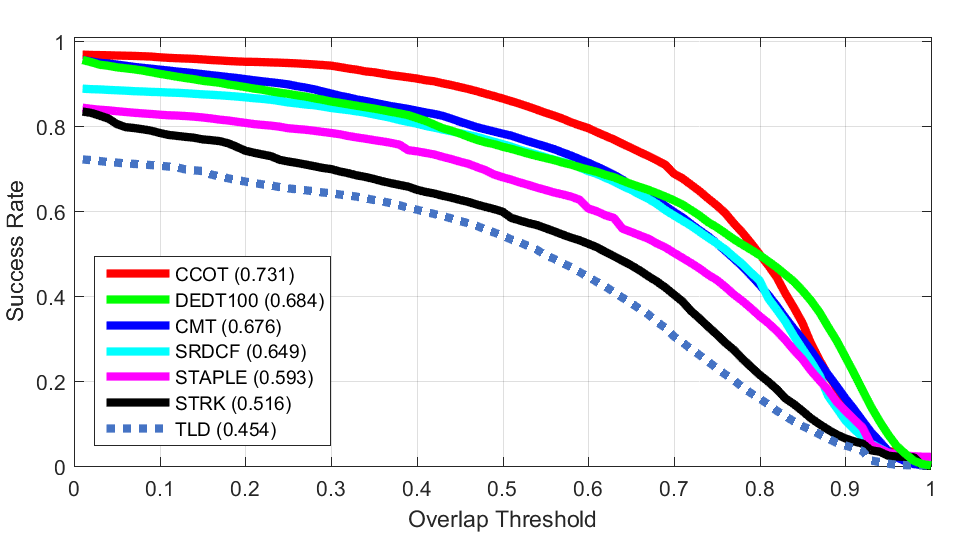 Fast
Fast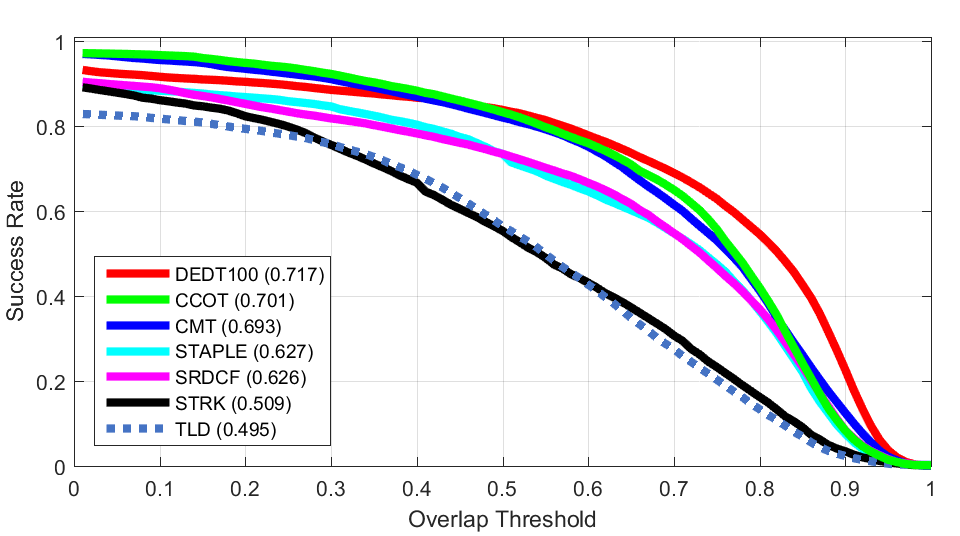 2D Rotation
2D Rotation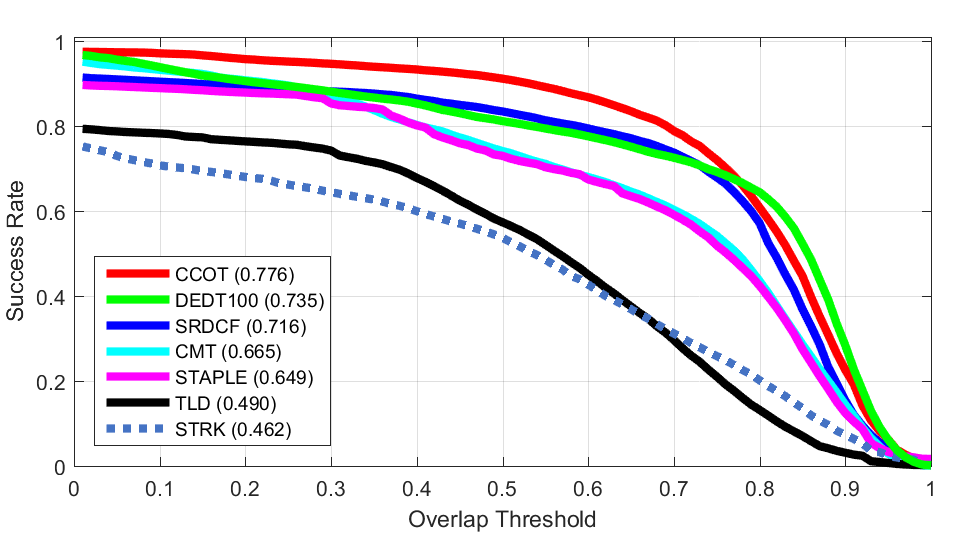 Lighting Change
Lighting Change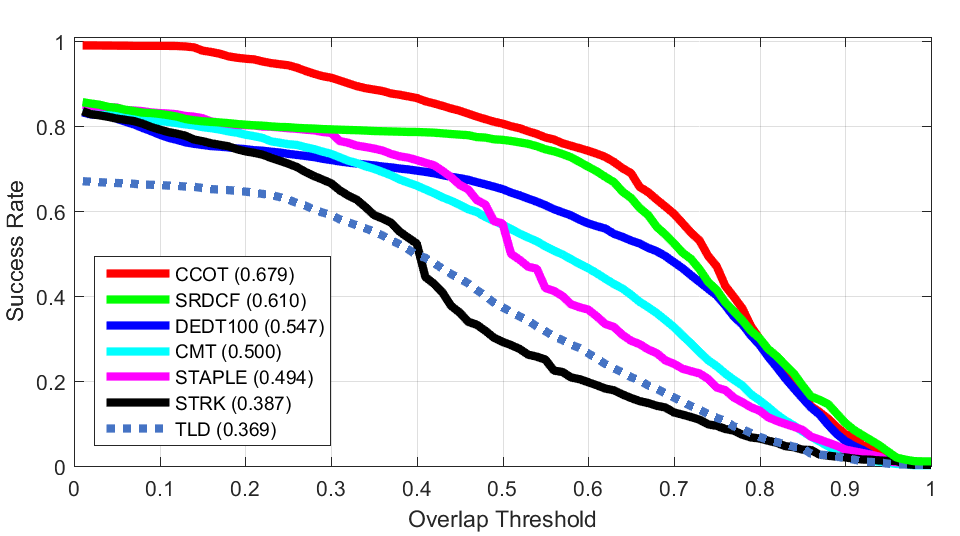 Low Resolution
Low Resolution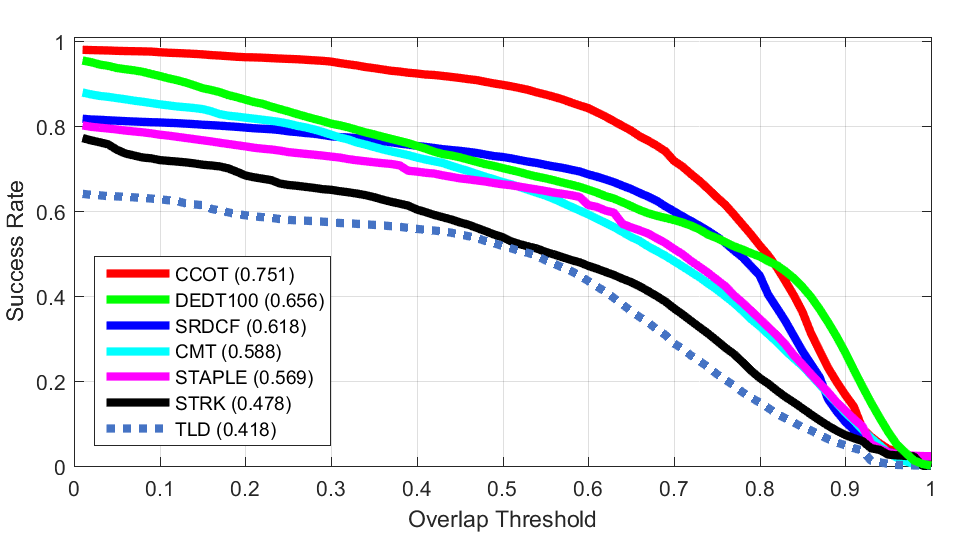 Blur
Blur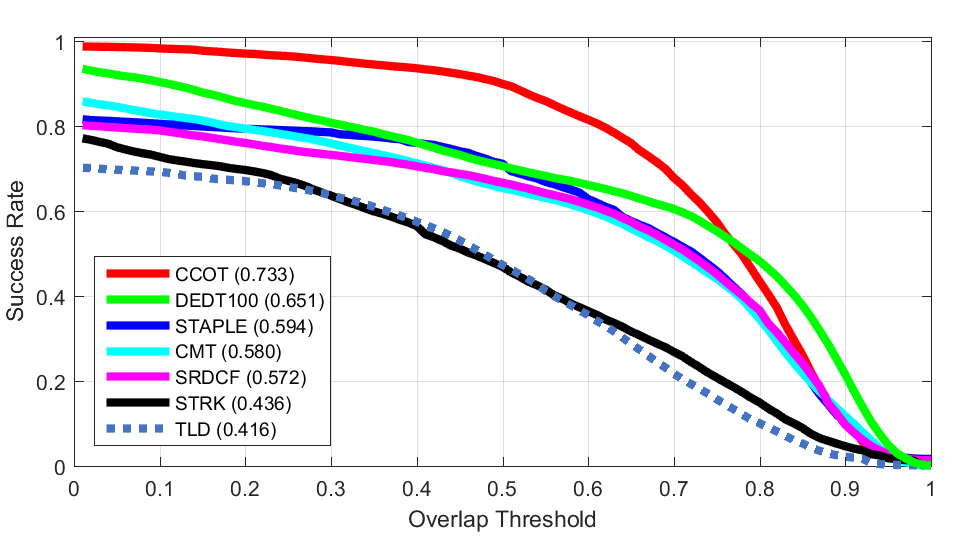 Occlusion
Occlusion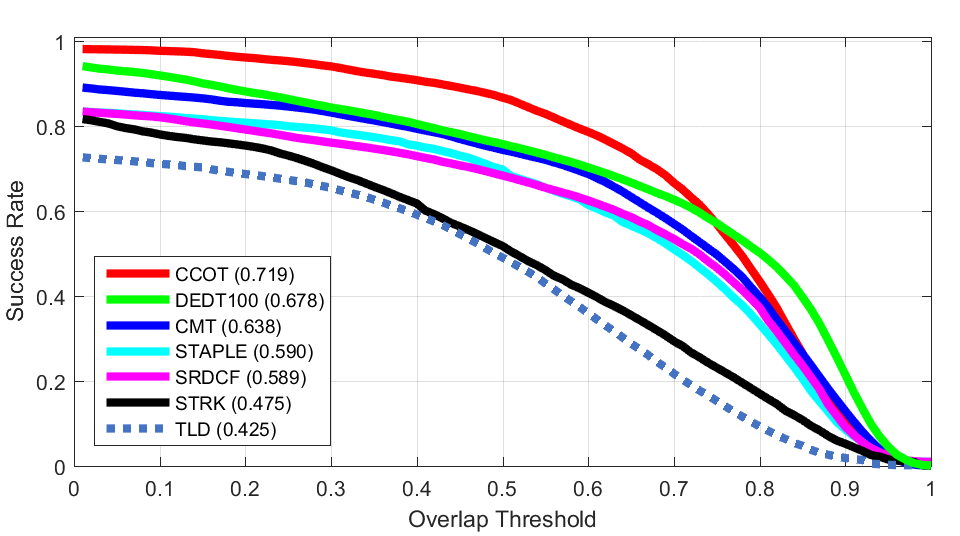 Z Rotation
Z Rotation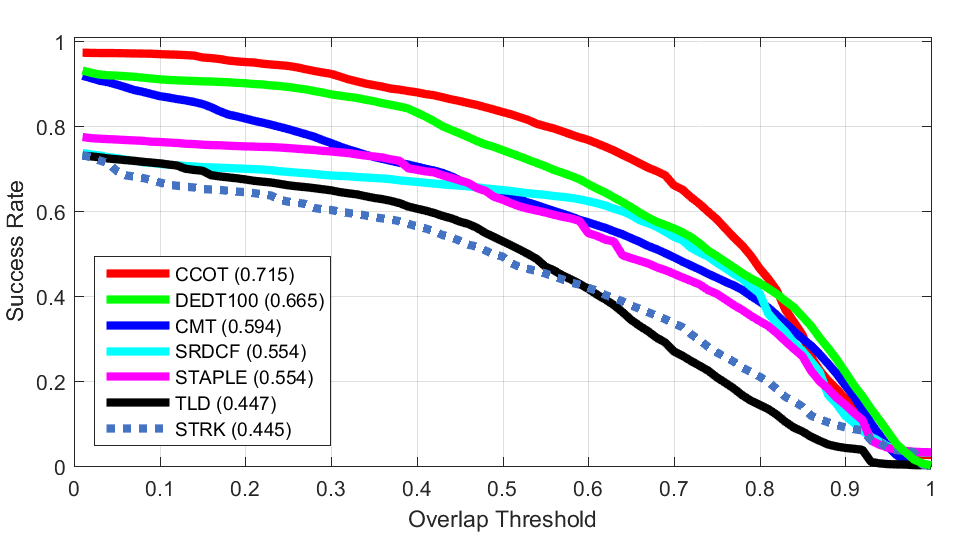 Shear
Shear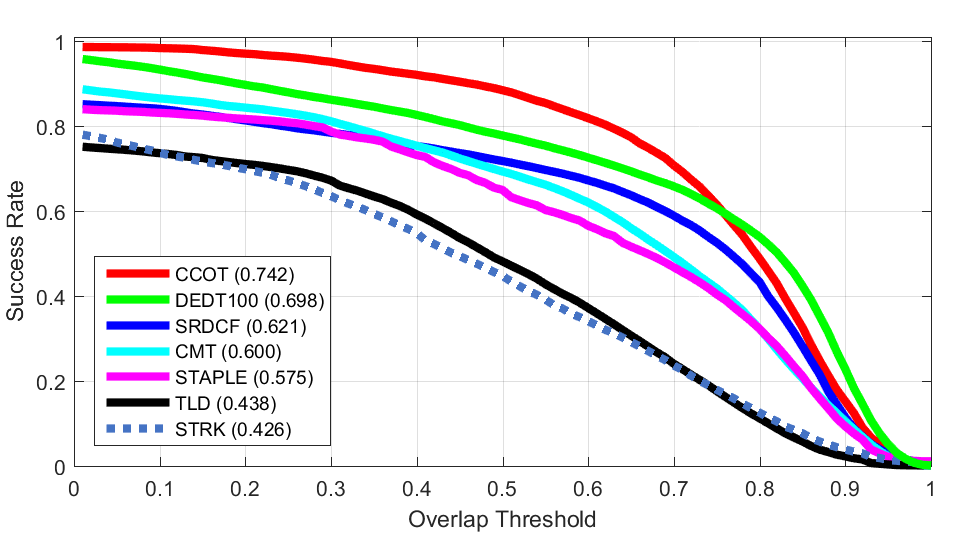 Scaling
Scaling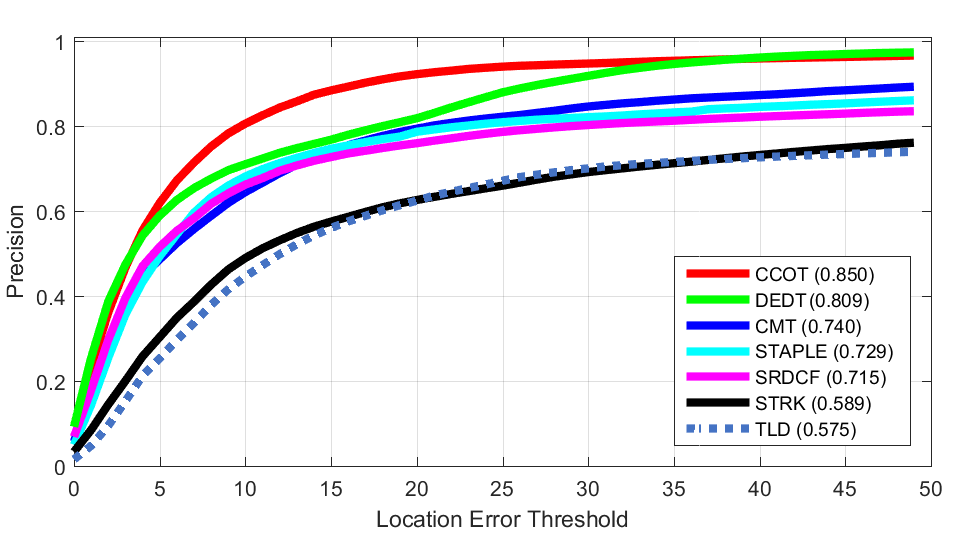 Precision Plot of ALL
Precision Plot of ALLOther Experiments
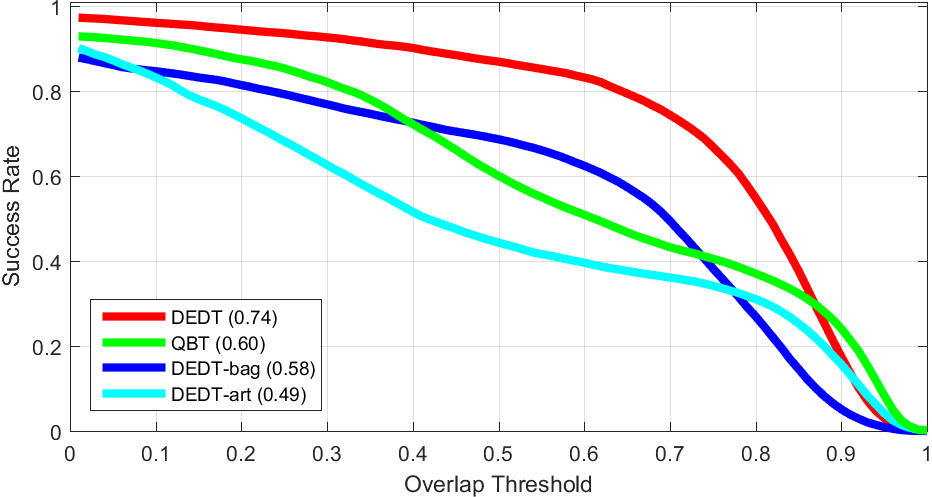 The effect of diversification procedure employed in the proposed tracker. DEDT-art only uses artificial data, DEDT-bag uses online bagging, and DEDT uses both to update their model.
The effect of diversification procedure employed in the proposed tracker. DEDT-art only uses artificial data, DEDT-bag uses online bagging, and DEDT uses both to update their model.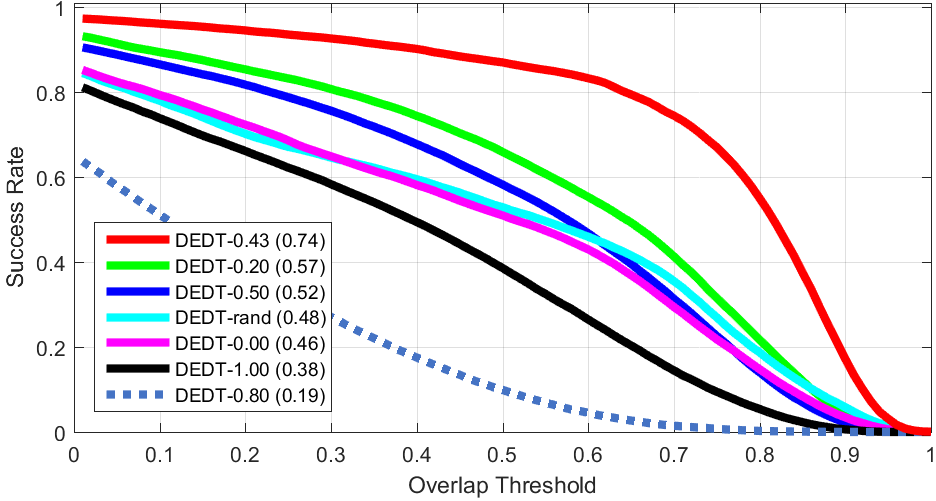 The effect of labeling thresholds on the performance of the proposed algorithm by controling the activeness of the data exchange between the committee and the auxiliary classifier, therefore allowing the ensemble to get more/less assistance for its collaborator.
The effect of labeling thresholds on the performance of the proposed algorithm by controling the activeness of the data exchange between the committee and the auxiliary classifier, therefore allowing the ensemble to get more/less assistance for its collaborator.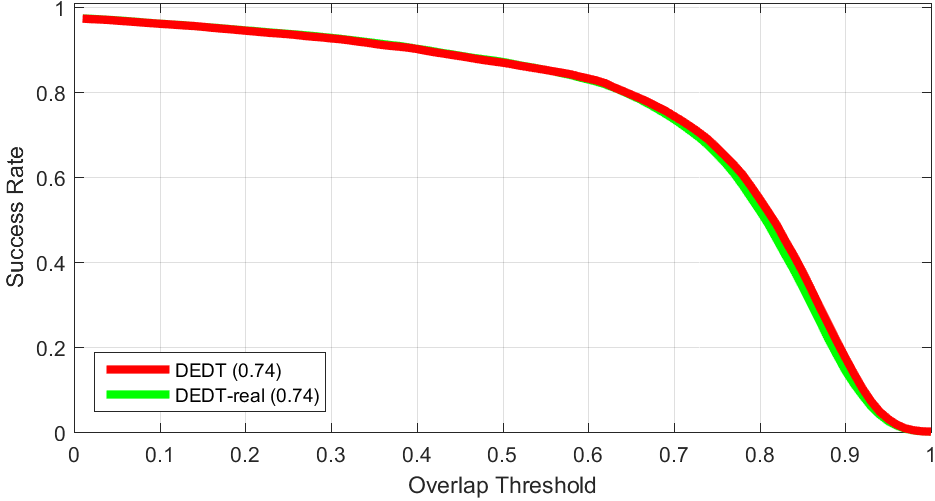 The effect of using Artificial Data: We look for the closest patch of the real image to the synthesized sample, and use it as the diversity data. The obtained tracker is referred as DEDT-real.
The effect of using Artificial Data: We look for the closest patch of the real image to the synthesized sample, and use it as the diversity data. The obtained tracker is referred as DEDT-real.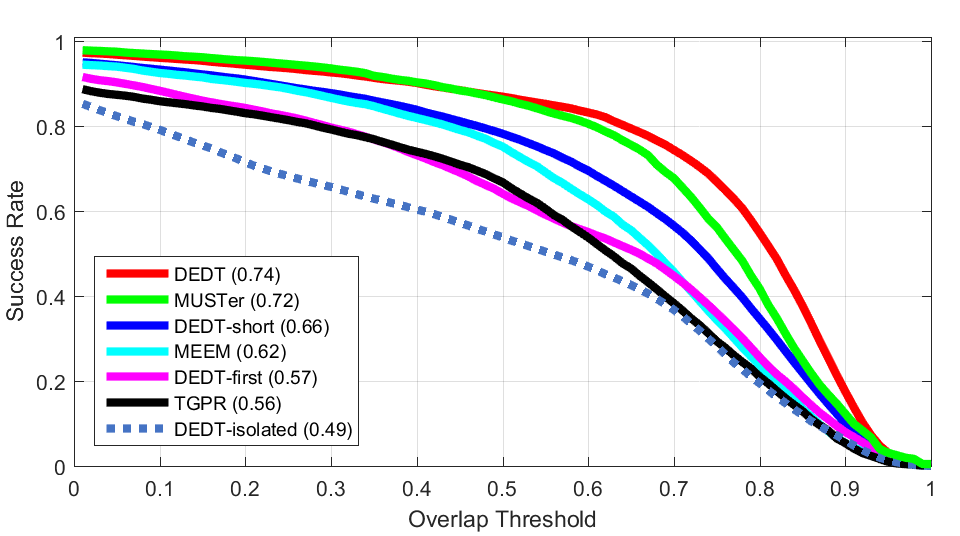 The effect of using long-term memory for auxiliary classifier of DEDT on the overall tracking results on OTB50. To see the performance of this scheme, we made DEDT-first that trains the auxiliary classifier on the first frame and do not update this classifier, DEDT-short that updates the auxiliary classifier on each frame, cancelling its long-memory properties, and DEDT-isolated that isolate the ensemble from auxiliary classifier
The effect of using long-term memory for auxiliary classifier of DEDT on the overall tracking results on OTB50. To see the performance of this scheme, we made DEDT-first that trains the auxiliary classifier on the first frame and do not update this classifier, DEDT-short that updates the auxiliary classifier on each frame, cancelling its long-memory properties, and DEDT-isolated that isolate the ensemble from auxiliary classifierBibTex reference
Download Citation , Google Scholar
@article{meshgi2017dedt,
title={Efficient Diverse Ensemble for Discriminative Co-Tracking},
author={Meshgi, Kourosh and Oba, Shigeyuki and Ishii, Shin},
journal={arXiv preprint arXiv:1711.06564},
year={2017}
}
Acknowledgements
This article is based on results obtained from a project commissioned by the Japan NEDO and was supported by Post-K application development for exploratory challenges from the Japan MEXT.
For more information or help please email meshgi-k [at] sys.i.kyoto-u.ac.jp.




{kind=link}